【Sora 在视频生成和模拟能力实现重大突破】
2 月16 日,OpenAI 发布最新文生视频大模型 Sora ,并在官网发布由其生成的 48 个视频样例。 目前,Sora 仍处于测试阶段,仅对部分评估人员、视觉艺术家、设计书和电影制作人开放访问权限。
Sora 在视频生成和模拟能力实现重大突破。基于通用视觉数据的模型 Sora 具有强大的功能,具体来看:
1)视频生成和处理能力:生成长达 1 分钟的视频,远超此前 Pika 的 7 秒、Runaway Gen2 的 18 秒,视频画面的表现和构图效果更佳。并且,生成视频具有3D 一致性,即可生成具有动态摄像机运动的视频,随着摄像机的移动和旋转,人物和场景元素在 3D 空间中保持一致移动。

2)图像生成能力:生成不同大小、分辨率最高可达 2048x2048 像素的图片。3)模拟能力:在 3D 空间中模拟人类、动物、 自然环境的特征,生成视频符合物理世界的规则。并且还能模拟数字世界、生成程序游戏。
【不仅是多模态,Sora 为世界模型的实现奠定基础】
此次文生视频模型 Sora 的发布是 OpenAI 继文字、图像之后,在内容生成领域的又一突破。同时,其强大的视频生成和模拟能力标志着 AI 技术在多模态领域实现重大突破。该模型强大的功能有望进一步优化内容创作者的视频制作流程,促进优质内容生产。并且,模型所具备的模拟物理世界和数字世界的能力或将加快世界模型的实现进程,推动游戏开发、虚拟现实等领域的发展。
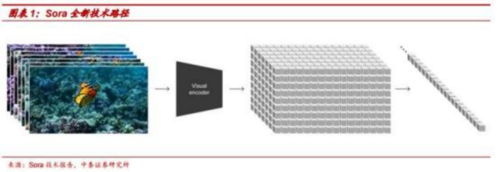
Sora 采用 Transformer 架构,并用 patches 作为训练和预测的基本单位。1)数据处理:类比于大语言模型将各种文本统一为 tokens, Sora 将不同的视频和图片等视觉数据压缩在低维潜空间中,将其分解为统一的 patches,以此作为视频大模型训练和预测的基本单位。2) 计算架构 :Sora 采用的是 duffis ion transformer 架构 , 即基于 transformer 编码器-解码器的架构,对经过增加噪点处理的 patches 进行编码,再通过解码器逐步还原出原始 patches 的预测。随着训练数据的增加,样本质量将显著提升。

【关注价值重估下的两大投资主线】
AI 多模态技术的出现,将各种内容形式与多种智能处理算法相结合,可实现不同内容形式间的相互转化。按形式进行划分,内容资产可分为文字、图片、音视频、游戏四大类。展望未来,随着多模态技术不断突破,文字、图片、音视频、游戏内容间的转化门槛将逐步降低,AI 辅助内容生成的比例将逐渐提升,长期来看 AI 生成有望占据主导地位。内容资产有望迎来价值重估,建议关注内容资产以及生成内容资产的 AI 工具两条投资主线:
1)内容资产:首推最低维的内容形式即文字类内容,且拥有内容数量多及质量高的公司弹性最大。文字作为最低维的内容被升维空间最大,有望全面受益于内容资产价值重估,而网络文学的娱乐性最强,因此其商业化空间最大。
2)生成高维内容资产的生产工具价值更高。1)AI 视频工具: 该领域海外公司表现更为突出,如 Runaway 的 Gen-1 和 Gen-2 、Pika Labs 的 Pika 1.0 、以及 OpenAI 最新发布的 Sora 。2)AI 音频工具:具备 AI 歌声进化功能的音乐社交 App 给麦,该功能能识别并抓取用户的个性化音色,让用户实现对多语种、不同风格音乐的演唱, 用户可授权 AI 用个人声音合成新歌曲;Meta 推出 AI 声音生成模型 Audio box ,实现根据文字或音频生成音频的功能。AI 游戏工具,通过模糊语音指令可实现数字资产的创建和细节调整,助力高度复杂的游戏开发。
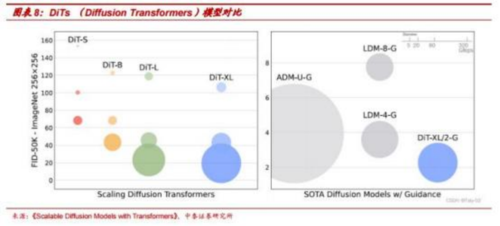
【相关受益图及参考标】
沪电股份---AI 带动算力基建需求大涨,公司业绩增长提速
长电科技---Q4 订单总额恢复至去年同期,多领域增长动能强劲
中文在线---2023 年净利同比预增 119%-129% 加码 AI+IP 双引擎战略












CopyRight@2008-2024 中国证券新闻 All Right Reserved
工信备案号:备案号京ICP(备)15095275
中国证券新闻版权所有违者必究




